https://docs.aws.amazon.com/ja_jp/athena/index.html
概要
Amazon Athena は、標準的な SQL を使用して Amazon Simple Storage Service (Amazon S3) 内のデータを直接分析することを容易にするインタラクティブなクエリサービスです。AWS Management Console でいくつかのアクションを実行するだけで、Athena にデータの保存先の Amazon S3 を設定し、標準 SQL を使用してアドホッククエリの実行を開始できます。結果は数秒で返されます。
料金
1TB あたり 約 5 USD
10MBのデータをスキャンさせた場合の料金は、10MB分の0.000005USD。
10MBに満たない場合でも同額になる。
ただし、1か月の利用料金の最低単位は0.01USDなので、
足りない場合は切り上げて0.01USDが請求される。
チュートリアル
とりあえず触ってみんべ。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/getting-started.html
最初のクエリを実行する前に、Amazon S3 でクエリ結果の場所を設定する必要があります。
以下をクエリエディタで実行する
create database mydatabase
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
`Date` DATE,
Time STRING,
Location STRING,
Bytes INT,
RequestIP STRING,
Method STRING,
Host STRING,
Uri STRING,
Status INT,
Referrer STRING,
ClientInfo STRING
)
ROW FORMAT delimited
FIELDS terminated BY '\t'
LINES terminated BY '\n'
LOCATION 's3://athena-examples-ap-northeast-1/cloudfront/plaintext';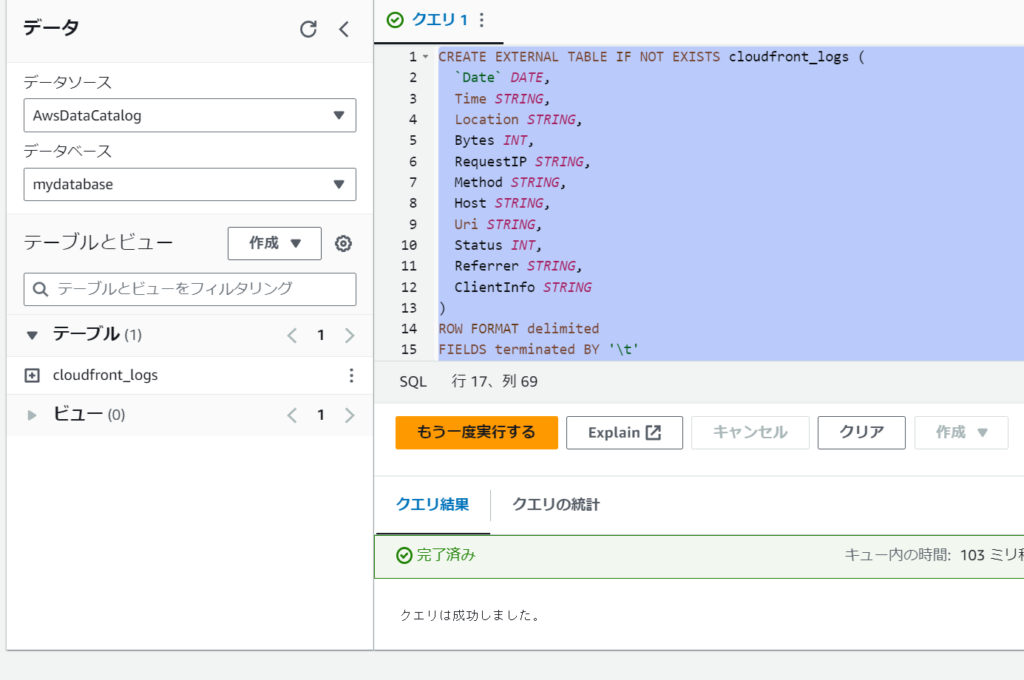
Mozilla/5.0%20(Android;%20U;%20Windows%20NT%205.1;%20en-US;%20rv:1.9.0.9)%20Gecko/2009040821%20IE/3.0.9
上記のような複数値フィールドを正規表現を使って、それぞれの列を作成する事もできるらしい。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES ("input.regex" = "regular_expression")チュートリアルでそんなこと書くと悩むんじゃない・・・?
と思ったら、後半もテーブル作成のクエリ書いていた。ややこしいね。DROP TABLEしないとだめだ。
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
`Date` DATE,
Time STRING,
Location STRING,
Bytes INT,
RequestIP STRING,
Method STRING,
Host STRING,
Uri STRING,
Status INT,
Referrer STRING,
os STRING,
Browser STRING,
BrowserVersion STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$"
) LOCATION 's3://athena-examples-myregion/cloudfront/plaintext/';